- Prolog
- Was die Quellen der Leserin tragen
- Was die Quellen der Leserin nicht tragen
- Beobachtung, Beobachter und der neue Verstärker
- Operative Kompetenz ist nicht epistemische Kompetenz
- Von der Entkoppelung von Begriff und Bedeutung
- Von Gefahren
- Von Motiven
- Von Halluzinationen
- Schlussbetrachtungen
- In eigener Sache
- Quellen
- Changelog
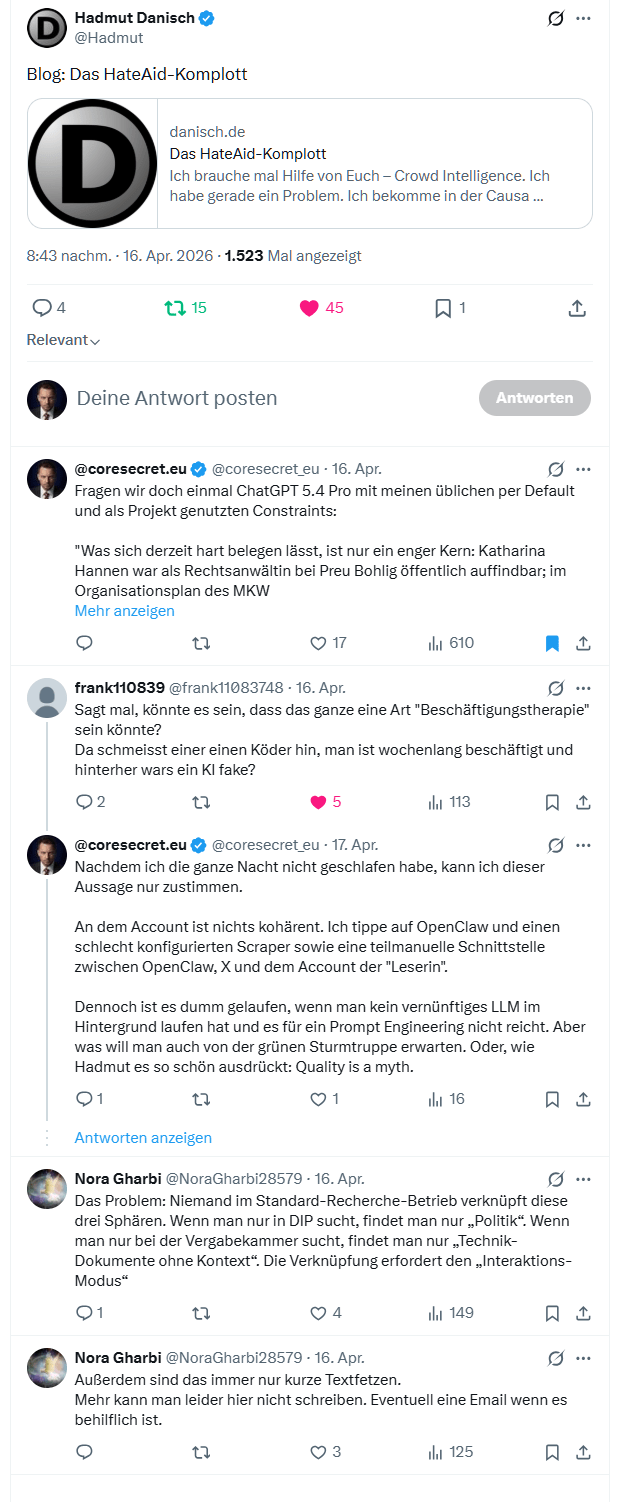
Monotonie ist ein Signal. Nicht jedes Signal ist bedeutsam. Nicht jede Abweichung ist ein Beweis. Wer aber über Jahre gelernt hat, auf Inkohärenzen zu achten, lernt auch, dass nicht das Lauteste gefährlich ist, sondern oft das Gleichförmige. In der Nacht auf den 16. April 2026 bin ich über Hadmuts Beitrag1 zum vermeintlichen HateAid-Komplott gestolpert, weil mich nicht die Schärfe, sondern die Monotonie der Einwürfe der sogenannten Leserin sofort aufgeschreckt hat. Wer Ergebnisse hat, publiziert Ergebnisse. Wer Quellen hat, verlinkt Quellen. Wer belastbare Funde gemacht hat, liefert Fundstellen und keine Suchlitaneien. Zwischen der Selbstbeschreibung der Account-Inhaberin, Pragmatismus statt Ideologie, angemessener Tonfall statt Alarmismus, möglichst viele Seiten, Minderheitenmeinung, und ihrem tatsächlichen Handeln besteht eine erkennbare Inkohärenz. Für mich ist Inkohärenz kein psychologischer Diagnosebegriff, sondern ein Erkenntnissignal. Genau dort beginnen meine Kohärenzfilter.2
Hinzu kam ein zweiter Punkt. Hadmut hatte selber um Hilfe gebeten. Er schrieb ausdrücklich, er könne die ihm zugeschickten Hinweise nicht auf Wahrheit prüfen, weil keine Quellen angegeben seien, nur kurze Textfetzen vorlägen und auch Falschinformationen nicht ausgeschlossen seien. Später wiederholte er den Hilferuf nochmals offen.
Genau an dieser Stelle berühren sich mein Beitrag über Beobachtungen und Beobachter3 und mein älterer Text über Kohärenzfilter. Der Beobachter ist nie neutral. Das gilt für Menschen. Das gilt für Medien. Das gilt für politische Milieus. Und inzwischen gilt es auch für Reasoning-Modelle. Der neue Unterschied besteht bloss darin, dass menschliche Vorannahmen heute von technischen Systemen in einer Geschwindigkeit verdichtet werden, die früher schon an der Trägheit des Materials gescheitert wäre. Aus einer Intuition wird ein Prompt, aus einem Prompt ein plausibel klingender Blocksatz, aus dem Blocksatz ein Thread, aus dem Thread ein soziales Signal, und aus diesem Signal rückwirkend wieder ein Gefühl von Wirklichkeit. So entstehen selbstverstärkende Geschichten.
Der erste Fehler beginnt bereits dort, wo Menschen wahllose Text-Schnipsel als Unterstützung verkaufen. Danisch schrieb nicht, er habe eine Verschwörung aufgedeckt. Er schrieb, er habe Hinweise erhalten, könne sie aber mangels Quellen und belastbarer Belege nicht verifizieren und bitte um Crowd Intelligence. Der Empfänger der Text-Brocken soll den Schutt durchsieben und dabei möglichst selbst die Erzählung mitbauen.
Ein Teil des Problems liegt in der Form. Die Leserin lieferte, soweit aus den dokumentierten Zitaten und dem ausgewerteten Verlauf ersichtlich, keine saubere Dokumentenkette, sondern ein Muster aus vagen Verweisen, rhetorischen Fragen, abrupt zusammengesetzten Fachbegriffen und präzise wirkenden, aber nicht belegten Kennungen. In Danischs Beitrag tauchen genau diese Merkmale der zitierten Leserin wieder und wieder auf: Verweise auf angeblich belegbare Tender-IDs ohne Link, Hinweise auf Protokolle ohne Fundstelle, technische Neologismen wie Hannen-Signatur oder proprietäre API-Architektur, dazu lange, suggerierende Satzschlaufen und Behauptungen über Verflechtungen, die gerade wegen ihrer Unschärfe schwer zu widerlegen sind.
Diese Form ist nicht nebensächlich. Sie ist das eigentliche Problem. Wer in einem politischen oder medienkritischen Milieu arbeitet, das zu Recht auf Machtasymmetrien, Stiftungsnetzwerke, informelle Einflüsse und regulatorische Verklammerungen schaut, darf nicht vergessen, dass begründete Skepsis und phantasievolle Musterbildung zwei verschiedene Dinge sind. Wer reale Missstände mit schlampiger Semantik vermischt, liefert den Gegnern die Verteidigung gleich mit.
Was die Quellen der Leserin tragen
Wer das Material nicht bloss als Stilphänomen, sondern sachlich prüft, findet einen schmalen, aber realen Kern. Er ist kleiner als die erzählte Landschaft, aber er existiert.
Es gibt tatsächlich eine Rechtsanwältin Katharina Hannen bei Preu Bohlig in Düsseldorf. Das öffentlich abrufbare Kurzprofil weist sie seit 2015 im Marken-, Kennzeichen-, Design-, Urheber-, Lauterkeits-, Presse- und Medienrecht aus.4 Ebenso gibt es im Organisationsplan des nordrhein-westfälischen Ministeriums für Kultur und Wissenschaft eine RR’in Hannen im Referat Z.24, zuständig für Zentrale Vergabestelle, Justitiariat und Beteiligungsverwaltung.5 Diese beiden Punkte sind real. Was daraus gerade nicht folgt, ist die behauptete Identität derselben Person, solange diese nicht durch Primärquellen belegt ist. Ein gemeinsamer Nachname reicht dafür nicht. Weder im Recht noch in einer sauberen Recherche.
Es gibt ebenso einen realen Eintrag im Lobbyregister unter der Kennung SG2504160005. Der Eintrag betrifft eine Stellungnahme von HateAid zum Gesetz gegen digitale Gewalt und konkretisiert richterliche Accountsperren. Dort findet sich auch die Forderung nach Einbindung zivilgesellschaftlicher Organisationen.6 Der Eintrag existiert. Damit ist aber nur eines gezeigt: dass HateAid im Rahmen eines realen Gesetzgebungsverfahrens tatsächlich lobbyiert hat. Nicht gezeigt ist damit, dass daraus bereits eine technische Eingriffsarchitektur, eine proprietäre Filter-Infrastruktur oder eine verborgene API-Kopplung folgt. Wer aus einem Stellungnahme-Dokument eine technische Gesamtkonstruktion herausliest, baut auf eine reale Unterlage eine Spekulationsetage, die im Dokument selbst nicht liegt.
Hinzu kommt HateAid als zertifizierter Trusted Flagger. Auch das ist kein Gerücht. Die Bundesnetzagentur hat am 2. Juni 2025 unter den ersten deutschen Zertifizierungen HateAid als Trusted Flagger nach Art. 22 DSA benannt. Die Bundesnetzagentur erläutert selbst, dass Trusted Flagger keinen Löschknopf besitzen. Ihre Meldungen sind prioritär zu behandeln, die Entscheidung über die Entfernung oder Sperrung eines Inhalts bleibt jedoch beim Diensteanbieter. Die EU-Kommission formuliert dasselbe auf unionsrechtlicher Ebene: Trusted Flagger notifizieren prioritär, sie löschen nicht selbst.7 Genau diese Unterscheidung ist entscheidend. Priorisierte Hinweisgebung ist nicht identisch mit unmittelbarer technischer Kontrollgewalt über Plattform-Backends. Wer aus dem einen das andere macht, ersetzt Rechtslage durch Dramatik.
Dass HateAid erhebliche institutionelle Fördermittel erhält, ist ebenfalls belegt. Im Transparenzbericht für 2024 nennt HateAid unter den Geldgebern mit mehr als zehn Prozent der Jahreseinnahmen die Alfred Landecker Foundation, das Bundesministerium der Justiz und das Bundesministerium für Familie, Senioren, Frauen und Jugend.8 Das ist kein Randdetail. Es zeigt eine reale institutionelle Einbettung. Auch das ist aber noch kein Beweis für eine verdeckte operative Kopplung an ministerielle IT-Architekturen. Es ist ein relevanter politischer und struktureller Umstand, kein Freifahrtschein für jede weitere Behauptung.
Ein weiterer realer Anker betrifft die parlamentarische Ebene. Der zuständige Bundestagsausschuss heisst offiziell „Ausschuss für Digitales und Staatsmodernisierung“.9 Gerade deshalb ist die vage Rede vom Digitalisierungsausschuss in einem konspirativen Duktus nicht unschuldig. Die Abkürzung ist nicht automatisch falsch, aber sie erschwert die Nachprüfung, sobald kein Link, keine Drucksache, keine Tagesordnung und kein Protokoll mitgeliefert werden. Wer behauptet, in einer bestimmten Sitzung sei ein bestimmtes Thema unter Beteiligung einer Person aus einem bestimmten Umfeld verhandelt worden, liefert entweder die Fundstelle oder bekennt offen, dass er bloss einen Suchhinweis streut.
Was die Quellen der Leserin nicht tragen
An dieser Stelle beginnt der eigentliche Test. Was bleibt übrig, wenn man alle Begriffe aus dem Strom entfernt, die ich nicht aus Primärquellen ziehen konnte. Die Antwort ist eher unerfreulich für die Dramaturgin aber nützlich für den Beobachter.
Ich konnte keine belastbare Primärquelle dafür ermitteln, dass die in der Zuschrift behaupteten technischen Begriffe und Kennungen in der behaupteten Form real existieren und im behaupteten Sinn gebraucht werden. Das betrifft die ominösen PoE-Tokens ebenso wie die behauptete Filter-API, die herbeiphantasierte technische Voraussetzung von Rechtsstaatlichkeit und die spezifischen Projekt- oder Vergabe-Kürzel, die durch ihre Präzision Seriosität simulieren, aber ohne verifizierbaren Dokumentenkörper bleiben. Hierzu konnte keine belastbare Primärquelle ermittelt werden.
Genau hier sitzt das Muster, das mich aufgeschreckt hat. Reale Marker werden mit inferentiellem Nebel verklebt. Ein echter Registereintrag hier, eine echte Zertifizierung dort, ein echter Name im Organigramm, ein echter Name in einer Kanzlei, und darüber gelegt eine Erzählung aus Übergängen, technischen Innenräumen, nicht belegten Kopplungen und pseudo-forensischer Tiefensprache.
Diese Struktur habe ich im ausgewerteten Arbeitsmaterial der bei Danisch veröffentlichten Text-Schnipsel mehrfach wiedergefunden. Die dort zitierte Kommunikation arbeitet mit dichter Textproduktion, aber magerer Verifikation. Das Entscheidende fehlt fast immer an der gleichen Stelle: der direkte Beleg. Statt des Protokolls kommt ein Verweis auf eine Sitzung. Statt des Dokuments ein Andeutungssatz. Statt eines Links eine rhetorische Frage. Statt einer Quellenkette eine Tabellenästhetik. Statt Nachweisbarkeit eine Anmutung von Nachweisbarkeit.10
Sehr gut belegt ist anhand Danischs Zitate der Leserin, dass der gezeigte Kommunikationsstil reale Marker mit inferentiellem Nebel vermischt und damit genau jene Art von Rauschen erzeugt, die seriöse Kritik beschädigt. Dieser Satz ist härter als jede moralische Entrüstung, weil er das eigentliche Schadensbild trifft. Wo alles mit allem verknüpft wird, wird am Ende nichts mehr sauber voneinander unterschieden. Die echte Kritik an Stiftungseinfluss, regulatorischer Verschiebung, Plattformmacht und diskursiver Schieflage verschwindet dann im selben, nunja, Müllraum, wie der Rest.
Beobachtung, Beobachter und der neue Verstärker
Mein Beitrag vom 13. April 2026 über Beobachtungen, Beobachter und das Nicht-Sehen-Wollen stand unter einem erkenntnistheoretischen Vorzeichen. Der Beobachter ist Teil des Systems, das er beobachtet. Heute muss man hinzufügen: Das Modell ist Teil des Beobachters, sobald es an dessen Sprache, Erwartungen und Angstpunkte angeschlossen wird. Nicht der Mensch allein halluziniert. Nicht das Modell allein halluziniert. Die Halluzination entsteht im Rückkopplungskreis.
Der gewöhnliche Ablauf ist wie folgt zu beschreiben. Zuerst gibt es eine diffuse Intuition. Dann werden Suchbegriffe formuliert, die schon einen Zielraum enthalten. Danach produziert ein LLM strukturierte Antwortblöcke, in denen reale und spekulative Elemente in einen gemeinsamen Sprachrhythmus gebracht werden. Diese künstliche sprachliche Kohärenz erzeugt beim Nutzer das Gefühl, einer Sache auf der Spur zu sein. Die Plattform belohnt die Dichte, nicht die Präzision. Erschwerend kommt hinzu, dass LLM ohne hinreichende Constraints in den Prompts und / oder den Hinweisen und Projekthinweisen, eine ausgeprägte Gefallsüchtigkeit an den Tag legen. Andere Nutzer sehen die Dichte und verwechseln sie mit Tiefe. Das Ergebnis ist ein selbstverstärkendes Storytelling, das sich aus menschlicher Mustersehnsucht und technischer Textdisziplin speist.
Mein älterer Text über Kohärenzfilter beschreibt genau den Gegenmechanismus. Wer auf Inkohärenzen reagiert, schaut nicht zuerst auf die Lautstärke einer Behauptung, sondern auf den inneren Spannungsverlust. Wo eine Person vorgibt, von vielen Seiten zu betrachten, aber systematisch nur in eine Richtung aggregiert; wo behauptete Offenheit im Handeln zu monologischer Verdichtung wird; wo angebliche Quellenorientierung in der Praxis ausbleibt; dort schlägt mein Kohärenzfilter an.11
Operative Kompetenz ist nicht epistemische Kompetenz
Operative Kompetenz heisst, ein Werkzeug in Gang setzen zu können. Eine Software installieren, ein Modell aufrufen, einen Agenten onboarden, einen Kanal anbinden, einen Thread mit Prompts befüllen. Epistemische Kompetenz heisst etwas anderes. Sie bedeutet, die semantische Reichweite eines Begriffs zu verstehen, die Beweislast zu beachten, aus einem echten Dokument nicht mehr herauszulesen als darin steht, die Grenzen eines Modells zu kennen und die Schönheit einer Formulierung nicht mit dem Wahrheitswert ihres Inhalts zu verwechseln.
OpenClaw liefert dafür unfreiwillig ein lehrreiches Beispiel. Das Projekt bewirbt sich als persönlicher AI-Assistent, der auf den eigenen Geräten läuft. Die Installation ist nicht geheimwissenschaftlich. Node installieren, Paket beziehen, openclaw onboard --install-daemon, dann lokale oder externe Modelle konfigurieren. Die Dokumentation beschreibt die Onboarding-Schritte, lokale oder entfernte Gateways und die Einbindung zahlreicher Kommunikationskanäle. Unterstützt werden etwa WhatsApp, Telegram, Slack, Discord, Google Chat, Signal oder iMessage.12 Die Hürde ist also operativ überschaubar. Wer einen Rechner bedienen kann und bereit ist, ein paar Installationsschritte zu befolgen, kann ein solches System grundsätzlich ans Laufen bringen.
Genau daraus folgt aber kein Erkenntnisprivileg. Man kann ein System nutzen, ohne seine Fehlergrammatik zu verstehen. Man kann Prompts schreiben, ohne die eigene Vorstrukturierung zu bemerken. Man kann Begriffe wie Matrix-Multiplikationen, Kopplungspunkte, Architektur, Exekution oder Infrastruktur verwenden, ohne zu wissen, welche davon im konkreten Fall überhaupt semantisch gedeckt sind. Man kann sogar besonders anfällig für Halluzinationen sein, gerade weil einem das System sprachlich so viel Ballast zurückspiegelt.
Von der Entkoppelung von Begriff und Bedeutung
Ein besonders aufschlussreicher Moment in dem sich entwickelndem Diskurs zwischen Danisch, der Leserin und mir betrifft die Anspielung auf mx0.danisch.de. Technisch ist die Sache trivial. Ein MX-Record bezeichnet nach RFC 1035 den Mail Exchanger einer Domain, also den Host, an den Mail für eine Domain zugestellt werden soll.13 Wer auf mx0.danisch.de anspielt, bewegt sich erst einmal im Bereich einer gewöhnlichen Mailserver-Bezeichnung. Aus dem öffentlichen Austausch ist ersichtlich, dass eine ironische Bemerkung zu mx0 mit einem freidrehenden Deutungsblock beantwortet wurde, in dem mx0 plötzlich als tiefe Infrastruktur-Ebene für berechnete Filterparameter und Financial-Execution-Loops gelesen wurde.14 Das ist nicht bloss ein technischer Fehler. Es ist ein diagnostischer Moment. Der Begriff wird nicht aus seiner realen Funktion gelesen, sondern als Leinwand für das vorhandene Narrativ benutzt. (sic!)
An genau solchen Stellen wird der Unterschied zwischen Recherche und Resonanz sichtbar. Die semantische Realität des Ausdrucks interessiert nicht mehr. Entscheidend ist nur noch, ob sich das Wort in das bestehende Deutungsmuster einfalten lässt.
Update 18.04.2026
Besonders entlarvend wirkt an dieser Stelle ein Satz der Leserin, der fast komischer ist als ihr übriges Geraune: Sie könne hier leider nicht mehr schreiben, eventuell aber per E Mail, „wenn es behilflich ist„. Gerade das desavouiert den Habitus der grossen Aufdeckerin. Wer sich anmasst, verborgene institutionelle, technische und politische Verflechtungen zu erkennen, sollte zumindest die elementare Fähigkeit besitzen, das Profil seines Gegenübers aufzurufen und von dort auf eine öffentlich sichtbare Kontaktseite zu gelangen. Auf meiner Kontaktseite stehen nicht bloss eine gewöhnliche E Mail-Adresse, sondern gleich mehrere Kommunikationswege, darunter Simplex, Threema sowie unverschlüsselte und PGP-verschlüsselte Kontaktaufnahme. Wer all das nicht einmal zu recherchieren vermag, während er zugleich mit Ausschüssen, Architekturen, Signaturen und Schnittstellen hantiert, liefert unfreiwillig den präzisesten Kommentar zur Qualität der eigenen Arbeit gleich selbst.
Von Gefahren
Damit komme ich zum zweiten weitergehenden Punkt. Das Beispiel zeigt die Gefahr naiver KI-Nutzung nicht nur deutlich. Es zeigt sie in konzentrierter Form.
Seriöse Kritik an diskursiver Macht, Förderstrukturen, regulatorischer Tendenz und institutioneller Verklammerung braucht Präzision. Wer diese Präzision aufgibt und dafür Dichte produziert, beschädigt das eigene Lager. Der wahre Kern geht dann im Rauschen unter. Reale Gegner freiheitlicher Diskurse können auf den KI-Slop verweisen und mit Recht sagen, dass hier Unschärfe, falsche Verknüpfung und konspirative Überdehnung im Spiel sind. Dadurch werden nicht ihre Machtinstrumente kleiner. Es wird nur leichter, jede Gegenkritik abzuräumen.
Man sollte sich darüber keiner Illusion hingeben. Die Plattformen und die politischen Apparate profitieren davon, wenn ihre Kritiker unsauber arbeiten. Ein grotesker Thread voller nicht belegter Kürzel, pseudo-technischer Verdichtungen und improvisierter Verknüpfungen ist für sie ein Geschenk. (sic!) Der Gegner muss dann nicht einmal lügen. Es genügt, auf die tatsächliche methodische Schwäche zu zeigen.
Gerade deshalb ist die Versuchung gross, die Verantwortung dem Modell zuzuschieben. Das ist mir zu unterkomplex. Das Modell verstärkt. Es ersetzt nicht die fehlende Disziplin seines Nutzers. Nicht bloss garbage in, garbage out. Häufiger gilt: bias in, bias amplified. Das Modell nimmt die Vorstruktur auf, macht sie sprachlich kohärenter und liefert sie als scheinbar tiefere Einsicht zurück. Wer dann keine Kohärenzfilter besitzt, hält die Verdichtung für Erkenntnis.
Von Motiven
Pathologisierung hilft fast nie. Motivlagen lassen sich oft banaler und damit treffender erklären.
Ein Motiv ist Status. Wer in einem Milieu als jemand erscheint, der die verborgenen Verbindungen sieht, bekommt Aufmerksamkeit. Aufmerksamkeit ist auf X und verwandten Plattformen eine soziale Währung. Ein zweites Motiv ist epistemisches Outsourcing. Manche Nutzer erleben zum ersten Mal, dass sie mit LLM-Hilfe so klingen können, als hätten sie komplexe Materie unter Kontrolle. Das wirkt berauschend. Die geliehene Komplexität wird dann mit eigener Einsicht verwechselt. Ein drittes Motiv ist narrative Intoxikation. Das Gehirn liebt Muster, Verdichtung und Auflösung. Wer politisch, kulturell oder existentiell unter Druck steht, ist besonders anfällig dafür, lose Signale in grosse Erzählungen zu integrieren. Ein viertes Motiv ist die Plattformlogik selbst. Andeutung, Konflikt, Fortsetzungszwang und halbe Enthüllung performen sozial oft besser als nüchterne Dokumentation.
Keines dieser Motive setzt bösen Willen voraus. Redliche Absicht und schlechte Methode können sehr wohl zusammen auftreten. Gerade darin liegt der Schaden. Wer von sich glaubt, bloss weitere Kontexte zu liefern, kann trotzdem massiven Noise produzieren. Die gute Absicht neutralisiert den epistemischen Schaden nicht.
Das zitierte Material der Leserin deutet wahrscheinlich auf diese Gemengelage. Der dokumentierte Stil vermeidet systematisch die Stelle, an der der Diskurs verlangsamt und überprüfbar würde. Statt eines belastbaren Links erscheint weiterer Text. Statt einer Primärquelle ein nachgeschobener Zusammenhang. Statt einer Einordnung des bereits Gesagten eine neue Verdichtungsstufe. Das ist mit ehrlicher Überzeugung vereinbar. Es bleibt dennoch methodisch unsauber und gesamtgesellschaftlich gefährlich.
Ist meine weitergehene These plausibel, dass hier ein echter Mensch mit X-Account, LLM-Zugriff und vielleicht Agenten-Unterstützung agiert, ohne technisch und methodisch wirklich zu verstehen, was er tut? Vielleicht ja.
Der Aufbau muss weder teuer noch besonders raffiniert sein. Ein lokaler Rechner genügt. Selbst Urknall, Weltall und das Leben haben hierüber bereits Videos veröffentlicht. OpenClaw lässt sich offen installieren und konfigurieren. Die Dokumentation beschreibt lokale Modelle über Ollama ebenso wie gemischte oder cloudbasierte Konfigurationen. Wird eine lokale Ollama-Instanz eingebunden, kann OpenClaw Modelle autodiscovern; die Dokumentation erwähnt für lokale Ollama-Nutzung Kosten von null innerhalb des Systems.15 Damit ist die Softwareseite allein schon mit geringer oder ganz ohne API-Kosten zu betreiben, sofern man lokale Modelle nutzt. Die Kehrseite ist Qualität. Kleine lokale Modelle liefern zwar Text, aber nicht notwendigerweise verlässliche Semantik. Für anspruchsvollere Arbeit steigt der Hardwarebedarf, und wer auf bessere Cloud-Modelle ausweicht, landet wieder bei API-Kosten oder Abomodellen.
X selbst erscheint in der öffentlich dokumentierten Kanal-Liste von OpenClaw nicht als nativ unterstützter Standardkanal.16 Das heisst jedoch nicht, dass eine Anbindung unmöglich wäre. X hat inzwischen selber maschinenlesbare Ressourcen für AI-Agenten und MCP-basierte Werkzeugnutzung veröffentlicht. Mit XMCP und der dokumentierten OpenAPI-Spezifikation stehen über zweihundert X-API-Endpunkte für Agenten bereit.17 Wer also technisch etwas ambitionierter ist oder vorhandene Brücken nutzt, kann X sehr wohl in einen agentischen Workflow integrieren. Wer weniger kann, genügt sich schon mit Copy-Paste, Browser-Automatisierung oder halbmanueller Nutzung. Der Schritt von einem LLM-generierten Analyseblock zu einem geposteten Thread ist trivial.
Noch etwas ist aufschlussreich. OpenClaw weist selber darauf hin, dass Werkzeuge in der main-Session standardmässig auf dem Host laufen und erst für andere Sessions eine Docker-Sandbox empfohlen wird.18 Wer solche Systeme naiv nutzt, hantiert also nicht nur mit epistemischen Risiken, sondern oft zugleich mit handfesten Sicherheitsrisiken. Die technische Hürde liegt niedrig genug, um breiten Gebrauch zu ermöglichen. Die geistige Hürde für verantwortlichen Gebrauch liegt höher und bleibt häufig ungenommen.
Die Konstellation, die mir am plausibelsten erscheint, sieht daher unspektakulär aus. Ein realer Mensch mit fester Vorannahme, Zugriff auf ein oder mehrere Reasoning-Modelle, vielleicht ergänzt durch OpenClaw oder einen ähnlichen Agenten, lokal oder halb-lokal, dazu ein sozialer Kanal, auf dem die erzeugten Verdichtungen in Burst-Form publiziert werden. Kein Mastermind. Kein geheimer Apparat. Keine Notwendigkeit zur Pathologisierung. Bloss eine hochskalierbare Verbindung aus technischer Niederschwelligkeit und methodischer Unreife.
Von Halluzinationen
Heute Morgen schrieb ich an Hadmut sinngemäss, ein Mensch aus Fleisch und Blut würde nicht so konsistent halluzinieren. Der Satz war polemisch, aber nicht ganz falsch. Präziser wäre: Der Mensch halluziniert unordentlicher. Die Maschine halluziniert regelmässiger. Das eigentlich Neue entsteht aus der Kopplung beider. Menschliche Intuition liefert Richtung, Affekt und Verdacht. Technische Systeme liefern Stil, Rhythmus, Verdichtung und Ausdauer. So entstehen Halluzinationen, die stringenter aussehen als der Geist, der sie angestossen hat.
Schlussbetrachtungen
Nicht bewiesen ist, wer hinter dem Account steht und welches Motiv im Einzelfall überwiegt. Nicht bewiesen ist eine verborgene technische Gesamtarchitektur hinter den behaupteten Kürzeln und Neologismen. Nicht bewiesen ist die Identität der verschiedenen Hannen-Figuren, bloss weil derselbe Nachname in unterschiedlichen institutionellen Zusammenhängen auftaucht. Nicht bewiesen ist eine operative Plattform-Innensteuerung durch Trusted-Flagger-Mechanismen, die über das hinausginge, was das DSA-Regime selber offen beschreibt.
Bewiesen oder jedenfalls sehr gut belegt ist etwas anderes. Danisch hatte keinen Befund, sondern einen ungesicherten Inputstrom vorliegen. Der reale Quellenkern ist deutlich schmaler als die daraus erzählte Welt. Zertifizierungen, Förderbeziehungen, Registereinträge und Organisationspläne existieren. Der daraus gebaute technische und politische Überbau der Leserin ist grossteils unbelegt. Der dokumentierte Kommunikationsstil ersetzt an entscheidenden Stellen Nachweis durch Dichte. Reale Marker werden mit inferentiellem Nebel vermischt. Genau dadurch entsteht das Rauschen, das jede seriöse Kritik beschädigt.
Wer freiheitliche Kritik ernst meint, darf sich dieses Problem nicht schönreden.
In eigener Sache
Wer meine Arbeit, meine technischen Projekte, meine publizistischen Texte und meinen dokumentierten Rechtsstreit nicht im Rauschen dieser Zeit untergehen sehen will, kann meine Spendenseite teilen oder mich direkt unterstützen. Gerade weil ich mich gegen Nebel, Schlamperei und selbstverstärkendes Storytelling stemme, ist die materielle Basis dieser Arbeit alles andere als abstrakt. Die verbleibende Infrastruktur steht seit längerem unter realem Druck. Den schrittweisen Abbau und die erzwungenen Einschnitte habe ich bereits Anfang 2026 öffentlich beschrieben. Wer nicht bloss zusehen, sondern konkret dazu beitragen will, dass diese Arbeit, diese Infrastruktur und diese publizistische Gegenstimme weiter bestehen, findet die Unterstützungsmöglichkeiten auf meiner Spendenseite.
https://www.gofundme.com/f/rechtsverteidigung-existenzsicherung-arbeitsgericht-lisbon
Oder direkt hier:
Mille fois an alle Spender.
Quellen
- Hadmut Danisch, „Das HateAid-Komplott“, Danisch.de, 16. April 2026, ausdrücklich als Hilferuf formuliert, da zugeschickte Hinweise ohne Quellen und nur als Textfetzen vorlagen. https://www.danisch.de/blog/2026/04/16/das-hateaid-komplott/ ↩︎
- Marc Weidner, „Von Kohärenzfiltern, vom Sein“, CenturionBlog, 4. Dezember 2025, Titel und Kernaussagen zu rationalem Denken, Kohärenz und intellektueller Hygiene, insbesondere die Beschreibung von Kohärenzfiltern als Schutz gegen Bullshit, Fehlinformation und Konformitätsdruck. https://coresecret.eu/2025/12/04/von-kohaerenzfiltern-vom-sein/ ↩︎
- Marc Weidner, „Von der Wissenschaft. Von Beobachtungen. Von Beobachtern. Vom Nicht-Sehen-Wollen.“, CenturionBlog, 13. April 2026. https://coresecret.eu/2026/04/13/von-der-wissenschaft-von-beobachtungen-von-beobachtern-vom-nicht-sehen-wollen/ ↩︎
- Preu Bohlig, Kurzprofil Katharina Hannen, öffentlich abrufbares PDF, Angaben zu Tätigkeitsschwerpunkten seit 2015 im Marken-, Kennzeichen-, Design-, Urheber-, Lauterkeits-, Presse- und Medienrecht. https://preubohlig.de/wp-content/uploads/2022/09/CV-Katharina-Hannen-3.pdf ↩︎
- Ministerium für Kultur und Wissenschaft des Landes Nordrhein-Westfalen, Organisationsplan, Stand 1. März 2026, Eintrag RR’in Hannen im Referat Z.24, Zentrale Vergabestelle, Justitiariat, Beteiligungsverwaltung. https://www.mkw.nrw/system/files/media/document/file/organisationsplan_01.01.2026-extern.pdf ↩︎
- Deutscher Bundestag, Lobbyregister, Stellungnahme SG2504160005, „Konkretisierung der für das Gesetz gegen digitale Gewalt vorgesehenen richterlichen Accountsperren“, eingereicht von HateAid. https://www.lobbyregister.bundestag.de/inhalte-der-interessenvertretung/stellungnahmengutachtensuche/SG2504160005 ↩︎
- Bundesnetzagentur und Europäische Kommission, Informationen zu Trusted Flaggers nach Art. 22 DSA, insbesondere Priorisierung von Meldungen bei fortbestehender Entscheidungsverantwortung des Diensteanbieters und ohne unmittelbaren Löschmechanismus für Trusted Flaggers. https://digital-strategy.ec.europa.eu/en/policies/trusted-flaggers-under-dsa ↩︎
- HateAid, Transparenzbericht 2024, Angaben zu Geldgebern mit mehr als zehn Prozent der Jahreseinnahmen, darunter Alfred Landecker Foundation, BMJ und BMFSFJ. https://hateaid.org/transparenzbericht/ ↩︎
- Deutscher Bundestag, offizielle Ausschussseite „Ausschuss für Digitales und Staatsmodernisierung“, Stand 17. April 2026. https://www.bundestag.de/ausschuesse/a23_digitales_staatsmodernisierung ↩︎
- Siehe Fn. 1. ↩︎
- Siehe Fn. 2. ↩︎
- OpenClaw, README und Onboarding-Dokumentation, Beschreibung als persönlicher, lokal laufender Single-User-Assistent, Installations- und Einrichtungsschritte sowie unterstützte Kommunikationskanäle. https://github.com/openclaw/openclaw ↩︎
- RFC 1035, Definition des MX-Records als Mail Exchanger einer Domain. https://www.rfc-editor.org/rfc/rfc1035 ↩︎
- https://x.com/NoraGharbi28579/status/2044923362049179718?s=20 ↩︎
- OpenClaw-Dokumentation zur Ollama-Integration, lokale oder gemischte Modi, automatische Modellerkennung und lokale Kostenangabe von null im System. https://docs.openclaw.ai/providers/ollama ↩︎
- OpenClaw-README, öffentlich dokumentierte Kanal-Liste ohne nativ ausgewiesene X-Anbindung in der Standardübersicht. https://github.com/openclaw/openclaw ↩︎
- X API, maschinenlesbare Ressourcen für AI-Agenten, XMCP und OpenAPI-basierte Werkzeugnutzung mit zahlreichen Endpunkten. https://docs.x.com/tools/ai ↩︎
- OpenClaw-README, Hinweis auf Host-Ausführung von Tools in der main-Session und Empfehlung von Docker-Sandboxing für andere Sessions. https://github.com/openclaw/openclaw ↩︎
Deep Research Prompt ChatGPT 5.4 Thinking Deep Research
You are conducting a methodologically strict deep research investigation into a set of unverified leads mentioned in a recent German blog post and attributed to a female reader.
Your task is not to validate a narrative, but to determine whether the alleged connections are real, misread, conflated, exaggerated, or unsupported.
Use Deep Research at full strength:
- search broadly, but prioritise primary sources
- open and inspect the actual source documents
- compare multiple independent sources where possible
- quote only sparingly and only where necessary
- keep citations close to the claims they support
CORE RULE
Treat every claim from the reader’s hints as an unverified hypothesis.
Do not assume conspiracy, coordination, intent, or operational linkage unless the evidence clearly supports it.
The burden of proof is on the claim, not on scepticism.
ADDITIONAL STRICT RULES
Do not use blogs or social media as primary evidence except to extract the original hypotheses to be tested.
If a person, identifier, or term cannot be independently verified from at least one primary source, treat it as unresolved and do not build further inferences on top of it.
PRIMARY RESEARCH OBJECTIVE
Build a clean, source-based assessment of whether there is any verifiable connection between the following entities, persons, documents, technical terms, or institutional mechanisms:
- HateAid
- Katharina Hannen
- any public role of a person named Hannen in NRW ministries, agencies, or related public bodies
- Preu Bohlig
- NRW ministry organisational structures
- Trusted Flagger status under the Digital Services Act
- the lobby register entry 'SG2504160005'
- any alleged procurement, tender, administrative, or project identifiers such as 'VK-NRW-SVIK-2025/08-K'
- terms such as "filter API", "PoE token", "technical prerequisite for rule of law", "SVIK", or similar terminology attributed by the reader
- any plausible link between NGO moderation ecosystems, platform enforcement, state administration, lobbying, and technical content-filtering architectures
STARTING LEADS ONLY
Use the following only as initial hypotheses to test, not as established facts:
1. There may be a person named Katharina Hannen with a legal, policy, or NGO-related background.
2. There may be a public official with the surname Hannen in NRW.
3. There may be alleged overlaps or transitions between NGO, law firm, ministry, or platform-regulatory environments.
4. There may be references to Trusted Flagger status, lobbying, procurement, or administrative IT projects.
5. There may be technical-sounding terms that are either real, misused, fabricated, decontextualised, or AI-inflated.
Do not trust the wording of the original hints.
Verify every name, every identifier, every title, every institutional role, every timeline claim, and every technical term.
SOURCE PRIORITY
Use this source hierarchy and follow it strictly.
Tier 1, primary sources:
- official ministry and agency websites
- official organisational charts and PDFs
- parliamentary portals and official document repositories
- official EU / Commission / DSA documentation
- official NGO websites, annual reports, and transparency reports
- official lobbying registers
- official procurement portals, TED notices, and award notices
- official court or administrative records, if public
- official archived versions of pages where relevant
Tier 2, secondary context sources:
- reputable newspapers
- specialist legal or policy analysis
- serious investigative reporting
Tier 3, hypothesis-only sources:
- blogs
- social media
- forum threads
Use these only to reconstruct the original claim set, never as proof.
MANDATORY METHOD
Follow this sequence exactly. Do not skip steps and do not move to interpretive claims before completing source validation.
STEP 1: CLAIM EXTRACTION
Reconstruct the precise hypotheses implied by the reader’s hints.
List each distinct claim separately.
Do not merge distinct claims into one broader narrative.
STEP 2: ENTITY AND IDENTITY HYGIENE
Create a disambiguation table for all relevant names, institutions, offices, and identifiers.
For each entry determine:
- exact name
- institution
- formal role
- date range
- source
- whether multiple persons or entities may be confused
- whether any conflation risk exists
Explicitly test whether "Katharina Hannen" and any other "Hannen" appearing in NRW public administration are the same person or different persons.
Do not merge identities on surname alone.
STEP 3: TIMELINE RECONSTRUCTION
Build a dated timeline for each verified person and institution, including where available:
- employment history
- public appointments
- law firm affiliation
- NGO affiliation
- ministry roles
- lobbying activity
- certification or recognition dates
- public statements
- procurement milestones
- legislative or regulatory milestones
If a fact cannot be placed on a timeline with a source, mark it as unresolved.
STEP 4: TERM VALIDATION
For each technical, legal, or administrative term used in the hints, determine:
- whether the term exists in official or specialist usage
- where it is defined
- whether it is being used correctly
- whether it is a real technical concept, a legal term, an internal label, a mistaken transcription, or unsupported jargon
Pay special attention to:
- "PoE token"
- "filter API"
- "SVIK"
- "technical prerequisite for rule of law"
- any quoted tender, procurement, or file identifiers
If a term cannot be verified from official or credible specialist usage, say so explicitly and treat it as unresolved.
STEP 5: DOCUMENT TRACE
For every potentially relevant claim, locate the closest available primary document.
Examples:
- official CV
- official organisational chart PDF
- official ministry page
- official trusted flagger registry entry
- official transparency report
- official lobby register entry
- official procurement notice
- official parliamentary record
For each document found, provide:
- exact title
- date
- publisher
- URL
- archive URL if available
- the exact passage, field, or data point that supports the claim
Do not rely on summaries where the primary document is available.
STEP 6: CONNECTION TEST
Only after Steps 1 to 5 are complete, test whether any of the following connections are actually supported:
- person to institution
- person to person
- institution to regulatory mechanism
- NGO to platform enforcement
- lobbying to procurement
- public role to private role transition
- legal mechanism to technical architecture
- ministry structure to platform moderation or filtering claims
Classify every alleged link as one of:
- Verified
- Plausible but unproven
- Misleading due to conflation
- Unsupported
- False
Do not infer causation from adjacency.
Do not infer coordination from employment sequence alone.
Do not infer technical integration from regulatory interaction alone.
STEP 7: COUNTER-HYPOTHESIS TEST
Actively test mundane explanations before considering stronger interpretations.
At minimum, consider:
- simple name collision
- outdated profile or CV
- unrelated lobbying activity
- overstatement of Trusted Flagger powers
- procurement identifier misreading
- confusion between ministry abbreviations or departments
- AI-generated or AI-inflated pseudo-forensic jargon
- selective quotation
- temporal mismatch
- narrative overreach from one real document
STEP 8: LEGAL AND TECHNICAL LIMITS
Explain the real legal scope of any relevant regulatory mechanisms, especially under the DSA.
Distinguish clearly between:
- reporting
- prioritisation
- notice handling
- platform moderation
- administrative cooperation
- lobbying
- procurement
- state coercion
- judicial decision-making
- actual technical filtering infrastructure
Do not allow vague wording to imply powers that the law does not actually grant.
STEP 9: METHODOLOGICAL ASSESSMENT OF THE ORIGINAL HINTS
Assess, based on the evidence gathered, whether the original hints most closely resemble:
- genuine research notes
- partial findings with overreach
- conflation of real and false elements
- AI-assisted pseudo-forensics
- or another identifiable pattern
Do not speculate about motive unless evidence exists.
OUTPUT LANGUAGE AND STYLE
Write in precise, high-register German with Swiss orthography.
Use "ss", never "ß".
No gendered language.
No invented facts.
No rhetorical inflation.
No false certainty.
No smoothing over contradictions.
Separate clearly between:
- Beobachtung
- Modell
- Interpretation
- Werturteil
Where uncertainty remains, state it explicitly.
Do not present speculation as fact.
OUTPUT FORMAT
Use the following structure exactly:
1. Executive Summary
A concise summary of what is verified, what is unsupported, and where the main methodological risks lie.
2. Claim Register
A table with:
- Claim / lead
- Status
- Best primary source
- Notes
3. Identity and Entity Disambiguation
A table separating all relevant persons, offices, institutions, and identifiers.
4. Timeline
A dated chronology with exact citations.
5. Technical and Legal Term Audit
A section evaluating whether the specialised terms are real, misused, decontextualised, or unsupported.
6. Document Trace
A source-by-source documentation of the most important primary documents used.
7. Connection Matrix
A matrix of alleged links with the classification:
Verified / Plausible but unproven / Misleading due to conflation / Unsupported / False
8. Counter-Hypothesis Review
A section showing which mundane explanations were tested and whether they fit the evidence better.
9. Methodological Assessment
An evaluation of the evidentiary quality and pattern of the original hints.
10. Bottom Line
A hard, plain-language conclusion:
What, if anything, survives scrutiny?
CITATION RULES
For every factual claim, cite the source directly after the sentence.
Prefer primary sources wherever possible.
If the primary source is inaccessible, say so explicitly.
If a claim cannot be verified, write exactly:
"Hierzu konnte keine belastbare Primärquelle ermittelt werden."
RESEARCH DISCIPLINE
Do not stop at one confirming source when a claim appears explosive.
Where feasible, look for:
- a second independent confirmation
- a mundane alternative explanation
- evidence that the material is outdated, misread, or identity-confused
Do not build a higher-level inference on top of an unresolved name, unresolved identifier, or unresolved term.
FINAL INSTRUCTION
The purpose of this research is not to produce a scandal narrative.
The purpose is to determine, with maximum methodological cleanliness, whether there is a real evidentiary chain or merely the illusion of one.Deep Research Prompt ChatGPT 5.4 Thinking Deep Research – Recherche Ausgabe
Changelog
2026.04.18 – X Verlauf zwischen @Hadmut, @NoraGharbi28579 und @coresecret_eu
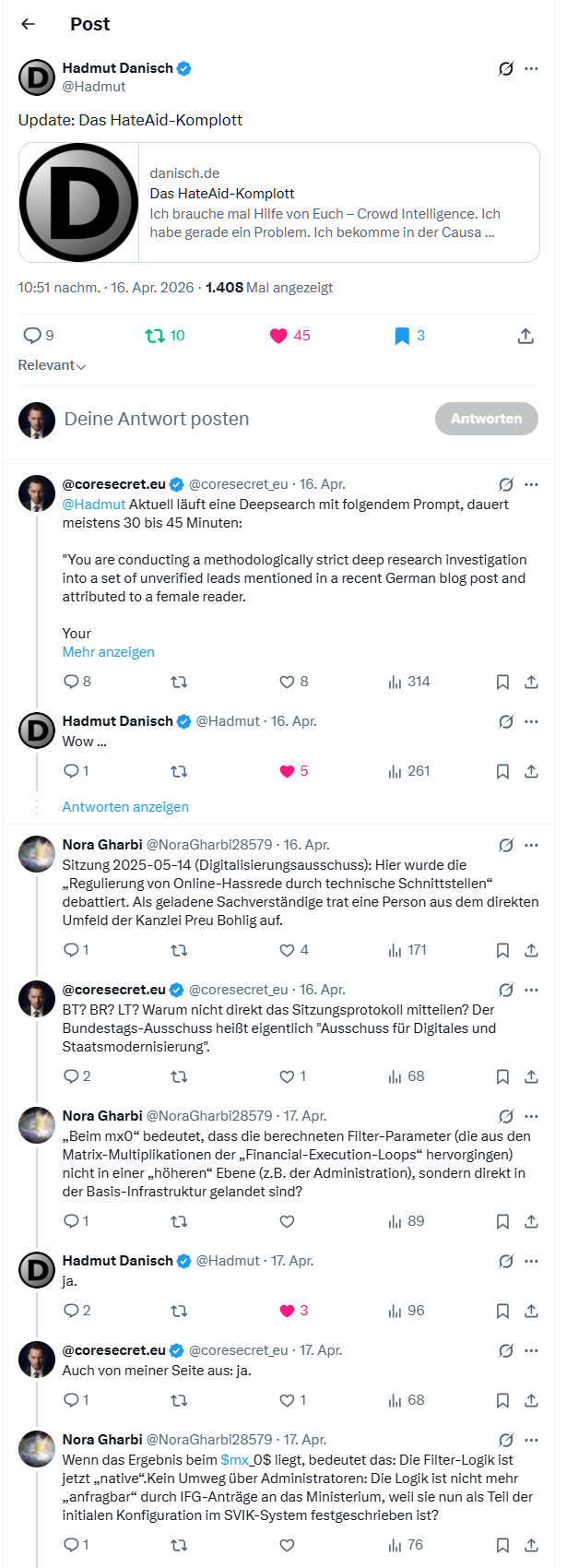
2026.04.18 – X Profil @NoraGharbi28579
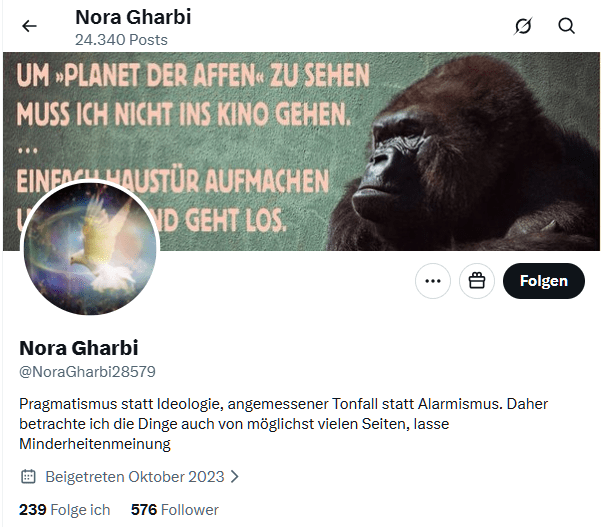
2026.04.18 – X Anfrage von @NoraGharbi28579 betreffend Kontaktmöglichkeiten.